SAP HANA innovation platform in SUPlabs
Voor de meeste SAP-ontwikkelaars is er waarschijnlijk weinig veranderd sinds de komst van SAP HANA eind 2010. Geen van onze klanten had immers SAP HANA en het zag ernaar uit dat dit ook nog wel even zo zou blijven. Ondanks dat, als je SAP zelf moest geloven, ging de hele wereld over op SAP HANA. Maar SAP HANA is toch alleen ‘een snelle database voor BW’? Niets is minder waar anno 2016!
Inmiddels heeft SAP groot ingezet met de lancering van ‘The next big thing’ in 2015: de release van S/4 HANA. We zien dan ook steeds meer SAP-georiënteerde klantorganisaties die SAP HANA op het vizier krijgen en dat het langzamerhand op de projectportfolio komt te staan. Dit betekent dat HANA development onomkeerbaar op ons afkomt. Het was dus hoog tijd om binnen SUPERP op een gestructureerde manier kennis over SAP HANA op te bouwen via ons kennis- en innovatieplatform SUPlabs. We hebben drie teams geformeerd om de ontwikkelingen vanuit verschillende disciplines op te pakken: development, functioneel en architectuur.
Vanuit deze invalshoeken hebben wij ons georiënteerd op welke facetten van SAP HANA interessant zijn voor ons als SAP-dienstverlener. Welke nieuwe technieken die we ons eigen moeten maken, komen erbij kijken? Welke mogelijkheden biedt het nou écht voor businessgedreven processen? Wat betekent de transitie naar SAP HANA voor onze klantorganisaties?
Al snel werd duidelijk dat het opdoen van kennis over de migratie van maatwerk naar een SAP HANA-database prioriteit moest krijgen. Een logische eerste stap voor veel klanten is immers het upgraden van hun huidige systeem naar een Business Suite on HANA. Sterker nog, wij gaan zelf deze kennis ook inzetten om onze eigen interne systemen te upgraden naar een Business Suite on HANA. In een later stadium groeit men dan door naar een volledig uitgerust S/4HANA-scenario.
Maar wat betekent deze migratie nu eigenlijk voor ons als developers en wat komt er allemaal bij kijken?
Code Push-Down
Iedereen kent SAP HANA als de supersnelle, in-memory database. Zodra je overstapt op SAP HANA gaat alles vele malen sneller. Maar is dit ook echt zo? Het antwoord op deze vraag is echter niet zo simpel. Ja, SAP HANA is heel snel, maar toegang tot de database is slechts een deel van de keten van een verzoek. Wanneer de data heel snel van de database terugkomt en er vervolgens op de applicatieserver nog zware berekeningen op losgelaten worden, zal het gehele verzoek er niet veel sneller op worden. Om zo optimaal mogelijk gebruik te maken van de kracht van SAP HANA, zullen er zoveel mogelijk data-intensieve berekeningen moeten worden verplaatst van de applicatieserver naar de database. Dit wordt door SAP het ‘Code Push-Down’ paradigma genoemd.
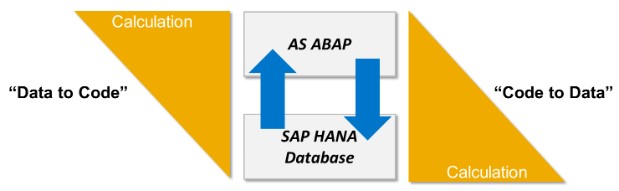
Concreet betekent dit, dat je op SAP HANA nieuwe views en/of tabellen zult moeten maken waarin je de data-intensieve berekeningen opneemt. Deze views kun je dan vanuit de ABAP code benaderen door gebruik te maken van ABAP External Views of ABAP CDS views. Op het moment dat je nu de view benadert, zullen de berekeningen op de SAP HANA database worden uitgevoerd. Je krijgt dan alleen het antwoord/de records terug die je nodig hebt in je ABAP, zonder dat je deze nog regeltje voor regeltje moet processen.
Corrigeren en verbeteren bestaand maatwerk
Door het verplaatsen van de data-intensieve berekening naar de SAP HANA database wordt alles dus sneller. Maar waar moeten we nog meer rekening mee houden als we overstappen naar een SAP HANA database. Dit is op te splitsen in twee categorieën:
1. Functionele aanpassingen: welke ABAP-code moet aangepast worden om potentiële technische en functionele problemen te voorkomen? Over het algemeen zal bestaande ABAP-code werken op SAP HANA, echter:
- Als ABAP-code afhankelijk is van specifieke database-eigenschappen, dient deze mogelijk aangepast te worden bij een migratie naar SAP HANA.
- Als ABAP-code afhankelijk is van het bestaan/gebruik van specifieke database-indexen, dient deze aangepast te worden bij een migratie naar SAP HANA.
- Tijdens de migratie naar SAP HANA zullen POOL en CLUSTER tabellen worden omgezet naar transparante databasetabellen. ABAP-code kan afhankelijk zijn van technische eigenschappen van POOL en CLUSTER tabellen. Deze code dient aangepast te worden bij een migratie naar SAP HANA.
2. SQL performance optimalisatie: welke code moet/kan worden aangepast om processen te versnellen (naast het verplaatsen van de data-intensieve logica)? Je wilt immers optimaal gebruikmaken van de rekenkracht van SAP HANA.
- Over het algemeen zullen er geen aanpassingen nodig zijn aan de ABAP code zolang deze zich houdt aan ‘golden Open SQL’ regels. Via checks uitgevoerd in de ATC( ABAP Test Cockpit) kan de code gevonden worden die niet aan deze regels voldoet. Combineer je deze kennis met runtime performance data (uit productie), waarmee je kunt zien welke stukken code veel tijd kosten om uit te voeren, dan kun je de code sorteren op ‘performance winst potentie’. Van hieruit probeer je dan de stukken code die het meeste impact hebben op je proces te verbeteren.
Voor het opsporen van maatwerkcode waar bovenstaande categorieën van toepassing zijn, bestaan enkele checks in de ABAP Code Inspector. Deze checks kunnen via de ABAP Test Cockpit (de ABAP Code Inspector is hierin geïntegreerd) worden uitgevoerd.
Het uitvoeren van deze checks geeft een lijst van code die verbeterd kan worden inclusief de manier waarop. De meeste SQL performance bevindingen zijn terug te herleiden naar onderstaande ‘Golden SQL Rules’. Deze regels gelden ongeacht de database die wordt gebruikt. Echter bij gebruik van SAP HANA zijn sommige regels nog belangrijker geworden vanwege de in-memory, kolom-gebaseerde aard van SAP HANA.
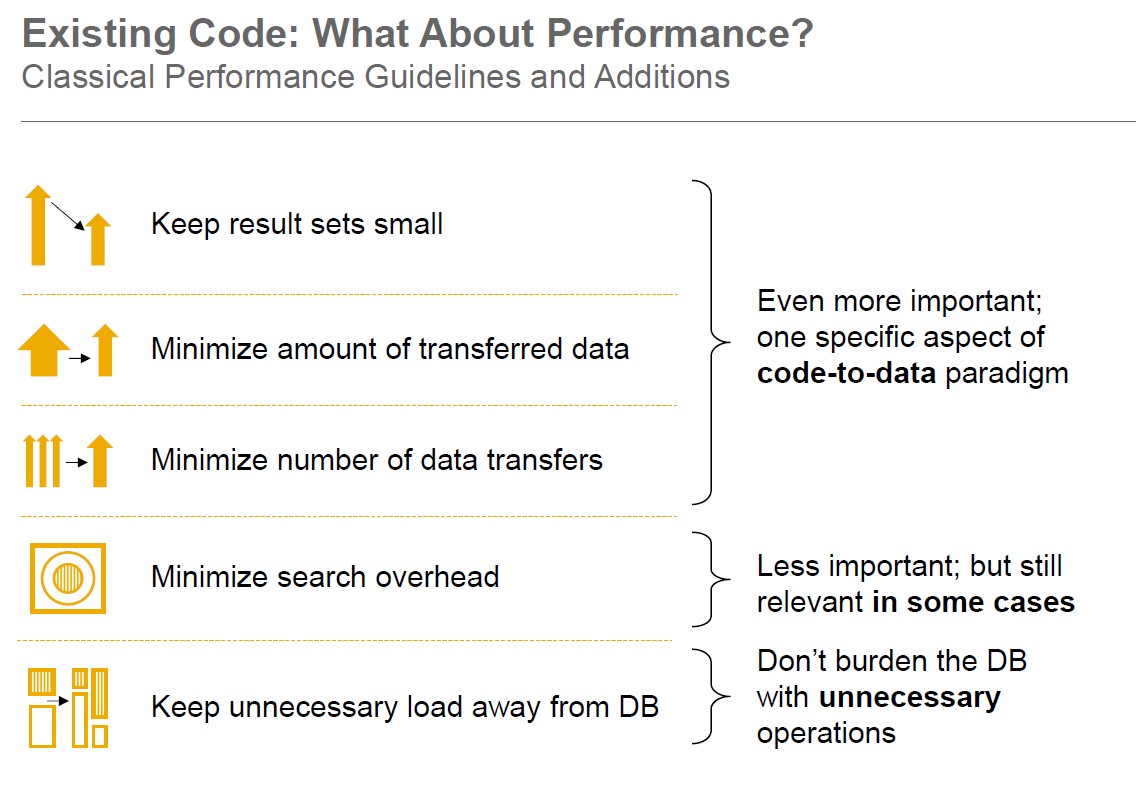
De ‘Golden Open SQL’ regels
Een kleine greep uit de interessante topics rondom een transitiescenario naar SAP HANA vanuit een development-perspectief. Uiteraard is nu het woord aan onze inventieve functionele collega’s, die procesoptimalisaties gaan uitwerken voor de primaire en ondersteunende processen in het SAP-systeem van de business. Wij kunnen het bouwen!!




